Anwendungsbeispiele der Statistik
Sozialwissenschaft
Mehrebenenanalyse (–> supervised Learning)
Anwendungsbeispiel PISA-Studie
Die internationale Pisa Studie testet im Jahre 2006 weltweit die Kompetenzen 15-jähriger Schüler in Kernfächern. Ein zweistufiges Stichprobendesign ergab 225 Schulen und in jeder Schule 25-30 Schüler.
Dieses Erhebungsdesign erzeugt eine hierarchische Datenstruktur, wobei der Schüler i die Ebene-1– und die Schule j die Ebene-2-Einheit bildet.
Die Schüler wurden einem zweistündigen Leistungstest unterzogen.
Ergebnisse: 1. Die Schulform prägt am stärksten des Leistungsvermögen der Schüler, wobei dies ebenfalls für die Testunterschiede der Migrantenschüler gilt. 2. Die soziale Segregation zwischen den Schulen beeinflusst die Schülerleistung viel stärker als die sozialen Unterschiede innerhalb des Klassenverbandes. 3. Die ethnische Segregation übt keinen eigenständigen Effekt auf die Schülerleistung aus, wenn Schulform und soziale Segregation kontrolliert werden.
Methodisches Resümee: Die Leistungsfähigkeit der Mehrebenenanalyse ist in der angewandten Bildungsforschung belegt.
Quelle: Wolfgang Langer. Mehrebenenanalyse mit Querschnittsdaten. In: Handbuch der sozial wissenschaftlichen Datenanalyse, VS-Verlag, 2010
Psychologie
Faktorenanalyse (-> unsupervised Learning)
Anwendungsbeispiel: Persönlichkeitsfragebogen
Ein kleiner Persönlichkeitsfragebogen besteht aus 3 Items
1. Ich fahre gerne Riesenrad
2. Ich liebe laute Musik
3. Ich habe Angst vor Spinnen
Ein mögliches faktorenanalytisches Modell könnte annehmen, dass hinter diesen drei Items zwei Faktoren stehen, nämlich Extraversion und Neurotizismus.
(Ergebnisse hier nicht veröffentlicht)
Medizin (Parodontologie / Implantologie)
Classifikation Tree (CART) (-> supervised Learning)
Anwendungsbeispiel: Vorhersage Knochenverlust
“The idea of validating a prognostic Model is generally taken to mean establishing that it works satisfactorily for patients other than those from whose data it was derived.” (DG Altman et al., Statistics in Medicine 2000, 19)
A Klassifikationsmethode: Classification Tree
Im Unterschied zur logistischen Regression, die das multifaktorielle Geschehen nur global abzubilden vermag, wird in dem binären Entscheidungsbaum das lokale Geschehen in Subgruppen erfasst.
B Instrument: Validierung (an einem unabhängigen Testset)
Ein Modell wird in diesem einfachen Setting entwickelt an ca. 70 % der zur Verfügung stehenden Beobachtungen (Patient*innen). Da man die Entwicklung des Modells auch als „Trainieren“ bezeichnen kann, spricht bei diesen Beobachtungen, die per Zufall aus den zur Verfügung stehenden ausgewählt werden, vom Trainingsset. Getestet (validiert) wird das Modell an den verbleibenden und damit statistisch unabhängigen 30 % (Testset). Modelle an allen zur Verfügung stehenden Daten zu trainieren und auch zu validieren, wie in der Medizin traditionell üblich, führt zur Überschätzung der Modellgüte und sollte der Vergangenheit angehören (es sei denn, man hat sehr wenige Patienten).
Kombination von Methode A und Instrument B ergibt den
Validierten Diagnosebaum (Validated Classification Tree)
Auf Basis von 70 % der Daten (balanciertes Trainingsset) kann man zwei Wochen nach Setzung eines Implantats für einen testnegativen Patienten (der 30 % unbalancierten Testdaten) mit einer Sicherheit von 93 Prozent vorhersagen, dass er ein knappes Jahr später keinen pathologischen Knochenverlust (KV) haben wird. Alter und Geschlecht (Frauen mit „1“ kodiert) sind die wichtigsten Prognosevariablen, gefolgt von Early Healing Index (EHI) 2 Wochen post implantationem und Anteil der Messstellen mit Bleeding on Probing (BOP) im Restgebiss.
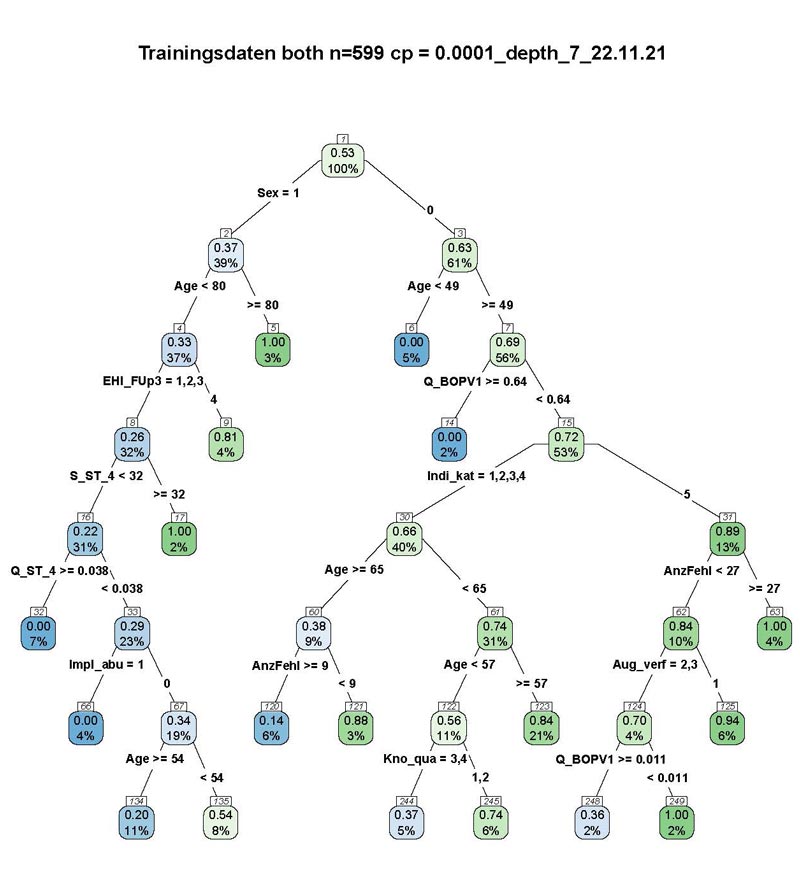
Legende: In jedem (mit Lücken durchnummerierten) „Knoten“ des Diagnosebaums gibt:
- der Prozentwert (untere Zahl) die relative Häufigkeit der jeweiligen Patientengruppe im Trainingsset (N=599) und
- der Anteilswert (obere Zahl) den Anteil pathologischer Knochenverluste in dieser Patientengruppe wieder.
- Blau hinterlegte Knoten haben einem Anteil < 0,50, grünhinterlegte einem Anteil >= 0,50. Je näher der Anteil an 0 oder 1, desto intensiver die Farbe.
Quelle: Eigene Datenanalyse